注意力机制
学习注意力机制的原理和实现代码
1.注意力机制
查询对象Query,被查询对象Value,通过去计算Q和V里的事物的相似度(更接近),来判断哪些东西对Q来说更重要,哪些更不重要。
Q,$K =k_1,k_2,\cdots,k_n$
通过点乘求内积的方法计算Q和K里的每一个事物的相似度,就可以拿到Q和$k_1$的相似度值$s_1$、Q和$k_2$的相似度值$s_2$、Q和$k_n$的相似度值$s_n$。计算$QK^T$后为避免输入的值差异过大导致Softmax的概率值过于极端,需要归一化,归一化的方式是除以嵌入向量维度的平方根。
做一层$softmax(s_1, s_2,\cdots,s_n)$就可以得到概率$(a_1,a_2,\cdots,a_n)$,进而找到哪个事物对Q更重要。
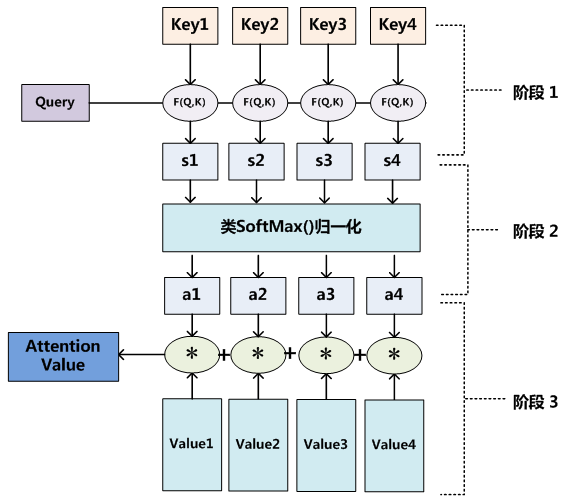
最后做一个汇总,拿到**经过注意力计算之后的图片$V’$**,现在这张图片中多了一些信息,多了于Q而言更重要、更不重要的信息。
$V=(v_1, v_2, \cdots, v_n)$
$(a_1,a_2,\cdots,a_n) *+(v_1,v_2,\cdots,v_n)=(a_1v_1+a_2v_2+\cdots+a_nv_n)$ = V’
2.自注意力机制(Self-attention)
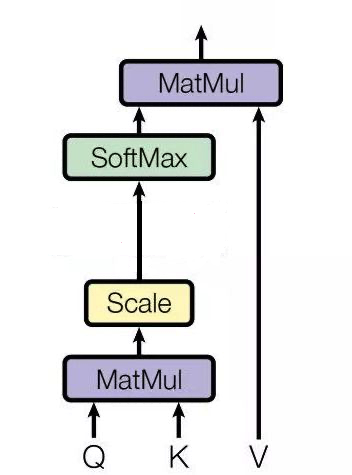
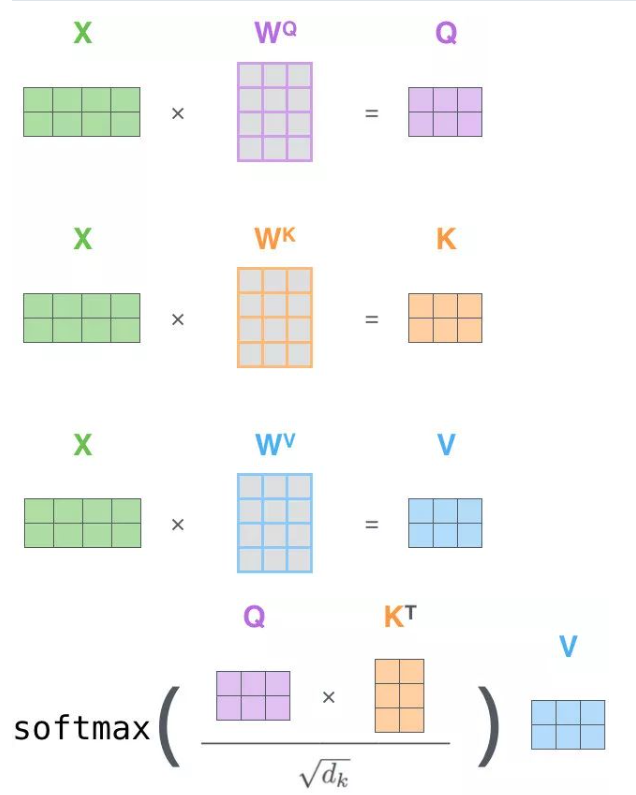
在注意力机制中,一般来说Key和Value是相等的,或者一定具有某种关系。而Self-Attention中, Query、Key、Value三者是同源的,即K$\approx$V$\approx$Q,来源于同一个X。
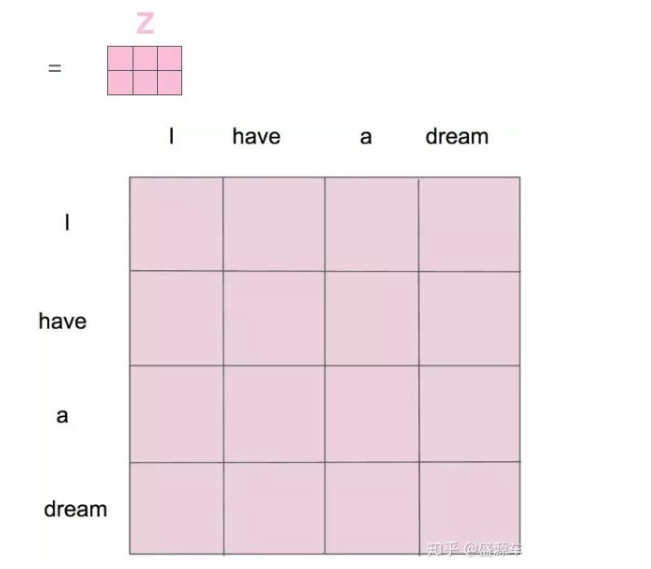
对X分别做三次线性变换,得到Query、Key、Value,通过X找到X里面的关键点。接下来的步骤和注意力机制一模一样,如图,列表示一个个X词向量,行表示分别要和句子中的每个词做一下相似度计算。
效果是:给定一个 X,通过自注意力模型,得到一个 Z,这个 Z 就是对 X 的新的表征(词向量),Z 这个词向量相比较 X 拥有了句法特征和语义特征。
3.多头自注意力(Multi-Head Self-Attention)
3.1 什么是多头
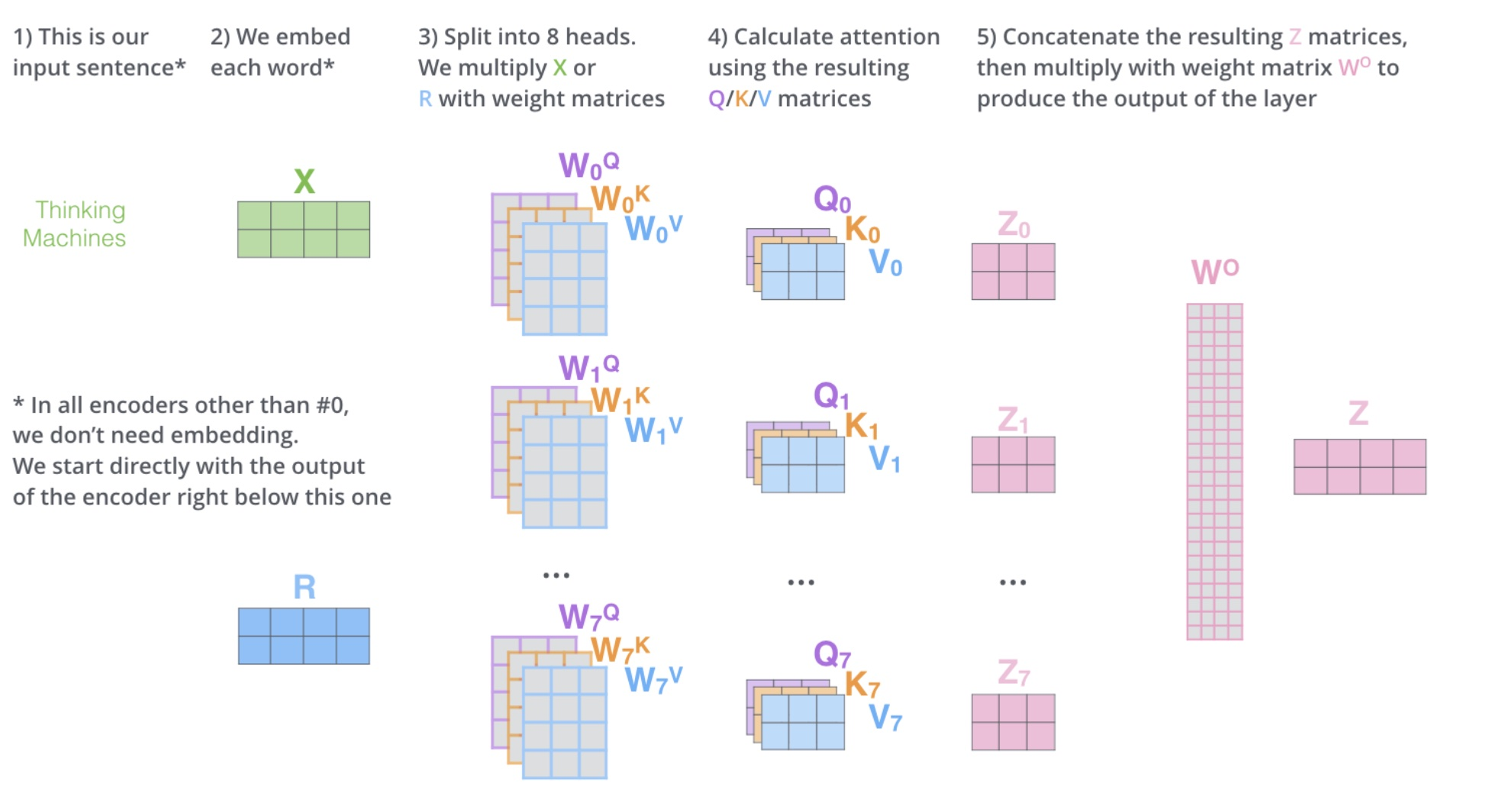
对于X,我们不是说,直接拿 X 去得到 Z,而是把 X 分成了 8 块(8 头),得到 Z0-Z7,然后把 Z0-Z7 拼接起来,再做一次线性变换(改变维度)得到 Z,使其和原来的X词向量维度一致。
3.2 有什么作用
把X切成8个,这样原先在一个位置的X,去了空间上的8个位置,通过对8个点进行寻找(非线性变换,映射到更合理的空间),找到更合适的位置。