度量学习思路整合
few-shot learning的度量学习方法阅读与总结,目标是找到一篇文章,解决few-shot的以下问题:
在基类上,模型学会区分相似和不相似的实例,从而提高下游任务的性能;
支持集的样本过少,计算得到的类代表原型和实际期望得到的类原型有较大偏差,如何矫正有偏的类原型,进而提高模型分类精度。
1.Prototype Rectification for Few-Shot Learning
1.1 基本信息
2020年,ECCV会议论文
无开源源码
提出了如何减少类原型的偏置、减少support和query dataset之间的分布差。
1.2 方法记录
1.2.1 intra-class bias
为了减少实际计算出的原型和真实原型之间的差距,采用伪标签策略,补充support set的样本,由此得到更接近真实的原型。具体操作是取top-k个置信度的未标记样本,加上伪标签,加入support set一起计算类代表原型,其中为了避免伪标签错分给原型带来大的误差,使用加权和的平均作为修改的原型,权重的计算公式:样本和basic prototypes有更大的余弦相似度,则在修改的原型中有更高占比。
伪标签有一个使用前提,即需要一次性给出某个类的所有未标记样本,不适用于一个个给测试样本的情况。
在脑电身份识别上,一个人作为一个类,他的测试样本是否可以一次性获取到?,决定了伪标签是否适用。
1.2.2 cross-class bias
首先两个set被假设为分布在同一个domain中,但support set和quary set之间存在分布差,提出为了减少两者的分布差,可以把quary set朝support set移动。具体地,文章提出给每个标准化后的quary feature$\overline{X_q}$添加一个转换参数epilon。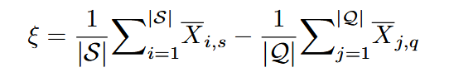
减小分布差,脑电身份识别,support set用的是登记session的样本,quary set可能用的是另一个session的样本,由于时变性,两者的分布差肯定是存在的,甚至于同一个session,随着人状态的波动,样本之间估计也存在明显的分布差,这个方法可以一试。
2.Free Lunch for Few-shot Learning: Distribution Calibration
2.1 基本信息
2021年,ICLR会议论文
提出从语义相似的基类(s)迁移统计数据来校准这些少数样本类的分布,接着依据新分布的均值和方差随机采样一定数量的样本,对novel classes的n_way k_shot任务的支持集进行补充,补充后的support set aug输入分类器fit。
2.2 方法记录
前提假设:假设特征嵌入的每个维度都服从高斯分布。
这篇代码基类是有充足样本的类,用别人的SOTA分类模型,取倒数第二层作为特征提取器,用于提取基类和novel类的特征嵌入。接着计算每个基类特征层面的均值向量和协方差。
测试类(novel classes)用的是轮次训练的方式,例如:
1 | |
每次从novel classes中抽5个类,每个类有1个support sample,15个query sample。每一次run,对抽取的5个support_data(先转成特征嵌入)分别做分布校准,然后生成若干个数的特征向量作为support集的补充,一起输入分类器fit,在query samples上测试,计算acc,最后取10000次run的平均acc。
分布校准core代码:
1 | |
- 这篇文章在细粒度数据集CUB上也应用了DC方法,有超过200种不同的鸟类图片。每个人的脑电虽然说各自有判别性特征,其实还是很相似的细粒度数据,这个方法通过迁移k个距离最小的基类的分布,来直接增加支持集的样本,进而提高分类性能。
- 要调的超参数多,采样个数、k个基类、离散程度a。
- 在脑电上是否有效呢?特征向量都是经过标准化/幂变换的。
3.Semantic-Based Implicit Feature Transform for Few-Shot Classification
3.1 基本信息
2024年,International Journal of Computer Vision
源码:SIFT
借鉴的是前面分布矫正的论文,同样是通过从基类补充特征向量到novel类上面去,不同的是图像类别标签(如cat、dog),本身具有语义信息,可以用不同的词向量来表达。然后通过语义嵌入的相似度来选择最近的基类,而不是前面通过统计特征。
3.2 方法记录
脑电的类别标签纯粹是'Person A'、'Person B'的形式,并不具有语义信息,所以如果要用,应该采用Free Lunch的方法做跨时段的分布矫正。
提出了一种原型矫正的方法。适用于transductive setting,即查询样本全部一次给出的情况。通过K-means把查询样本分簇为N类,接着建立路径规划问题的数学模型,为这N个类别确定互相不重复的标签,与初始的每个类原型做平均。
1 | |
4.Matching Feature Sets for Few-Shot Image Classification
4.1 基本信息
2022年,CVPR会议论文
源码:SetFeat-fs
以Conv4-64骨干网络为例,提出把一张图像输入进去,经过一个Block,就输出一个经自注意力机制mapper计算后的特征向量$h_m$,这样处理从一张图片中提取出一组m(4)个特征向量。距离度量用的是负余弦相似度,实际上和原型网络的距离度量很相似,区分在于有多个特征向量,它这里统一了向量的shape,相当于在同一个特征空间内,按mapper聚合多个类中心。
4.2 方法记录
如何利用多个不同层提取出的特征向量,核心如下公式所示。
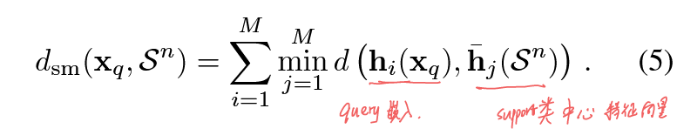
训练流程:两个阶段,第一阶段就是正常带FC层的分类器,并且本文是在每个Block后面都接一个FC层,分别训练到这个Block为止的网络,第二阶段,舍去FC层,应用轮次训练在基类上模拟FSL Task,通过公式6的负对数概率计算loss,反向传播微调编码器的参数。微调结束,最终在novel类上面推理,之前的Free Lunch也是一样的流程。
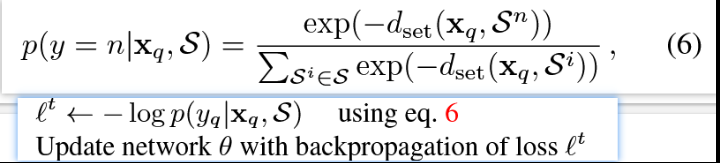
- 总结一下,它提高原型网络分类精度的手段就是,同一个特征space,一个类别聚合m个类中心。
- 感觉第一阶段训练就相当于独立地训练了4个encoder,但是又不独立,前面的参数是要重复使用的,具体要看代码train部分。
- 这种在预训练阶段,训练一个分类器的做法和我之前看的有监督对比学习训练编码器的方式不一样,我的想法是也许可以借用这个metric,然后用SCL的做法分别独立训练出3个encoder。之后可以有两种metric方法,一种是和本文做法一样,投射到同一个特征空间;另一种映射到不同特征空间分别做相似度计算,再求和,作为新的metric。
- 还有一个想法是SCL的encoder很关键,决定了特征向量的质量,借鉴GoogleNet的多尺度卷积方法,预训练出一个encoder,也可以试一下。
4.3 参考博客
5.BSNet: Bi-Similarity Network for Few-shot Fine-grained Image Classification
5.1 基本信息
2020年,IEEE Transactions on Image Processing(TIP)期刊论文
源码:BSNet
代码格式简洁,是基于度量学习的图像细粒度分类,提出同时使用余弦相似度和欧式距离两种loss,即在ProtoNet上添加一个余弦相似度的loss,分类精度在图像分类上有所提高。
最后调优模型的时候可以试一下,有空看代码。
6.Supervised Contrastive Learning
6.1 基本信息
2020年,NeurIPS
源码:SupContrast
SCL集合了传统度量学习领域的Triplet loss、N-pair loss两者的特点,提出对一个Anchor除了考虑多个负样例之外,也同时考虑多个正样例,设计的损失函数避开了需要显式地调参以挖掘半难样本的需求。
6.2 方法记录
在一个batch中,每一个样本$x$都经过一个数据增强模块$Aug(·)$生成两个随机增强$\bar{x} = Aug(x)$,两个增强后的样本标签一样,属于同一个类别。接下来如何保证随机生成的一个batch有多个样本标签相同呢,除了数据增强的方式生成正样本对之外,相对于类别个数大小C,batch的
batch_size = N要远大于C,这样平均N/C,就必定会采样到同一个类的多个样本。代码与对应公式的解释:监督对比学习SupConLoss代码学习笔记
1 | |
仿照这篇论文的三个核心模块:数据增强模块、编码网络、映射网络,计划对脑电原始数据做Channel Reflection数据增强,以及一个其他数据增强操作,和本文的监督对比loss匹配,Backbone也需要找一个替换。
7.Channel reflection: Knowledge-driven data augmentation for EEG-based brain–computer interfaces
7.1 基本信息
2024年,Neural Networks
源码:EEGAug
提出了一种无需超参数的通道交换(CR)数据增强方法,传统的数据增强如添加Noise、Scale、Frep都需要调超参数,并且十分鲁棒,在MI、SSVEP、ERP、癫痫检测4个实验范式下均适用,相比于Baseline(没有数据增强),分类精度更好。注意经CR数据增强之后,训练数据翻倍。
7.2 方法记录
1 | |
- 即根据脑电极通道的索引,位于中线的电极不变,左脑和右脑对称分布的电极做一个交换,类似于图像的翻转操作。除左右手MI想象要调换标签之外,ERP不需要换标签。调用方法如下:
1 | |
8.Charting the Right Manifold: Manifold Mixup for Few-shot Learning
8.1 基本信息
2020年,WACV
源码:S2M2_fewshot
提出…